Lógica de la Aplicación ORM – Apoyo a los Procesos de Negocio
En este capítulo, aprenderá como escribir código para soportar la lógica de negocio en sus modelos y también como puede esto ser activado en eventos y acciones de usuario. Podrá escribir lógica compleja y asistentes usando la API de programación de Odoo, lo que les permitirá proveer una interacción más dinámica con el usuario con estos programas.
Asistente de tareas por hacer
Con los asistentes, podrá pedir a los usuarios que ingresen información para ser usada en algunos procesos. Suponga que los usuarios de su aplicación necesitan fijar fechas límites y personas responsables, regularmente, para un largo número de tareas. Podrá usar un asistente para ayudar con esto. El asistente permitirá escoger las tareas que serán actualizadas y luego seleccionar la fecha límite y/o la persona responsable.
Comenzara por crear un módulo nuevo para esta característica:
todo_wizard. Nuestro módulo tendrá un archivo Python y un archivo
XML, por lo tanto la descripción todo_wizard/__openerp__.py será
como se muestra en el siguiente código:
{
'name': 'To-do Tasks Management Assistant',
'description': 'Mass edit your To-Do backlog.',
'author': 'Daniel Reis',
'depends': ['todo_user'],
'data': ['todo_wizard_view.xml'],
}
El código para cargar su código en el archivo
todo_wizard/__init__.py, es solo una línea:
from . import todo_wizard_model
Luego, necesita describir el modelo de datos que soporta su asistente.
Modelo del asistente
Un asistente muestra una vista de formulario al usuario, usualmente dentro de una ventana de dialogo, con algunos campos para ser llenados. Esto será usado luego por la lógica del asistente.
Esto es implementado usando la arquitectura modelo/vista usada para las
vistas regulares, con una diferencia: El modelo soportado esta basado en
models.TransientModel en vez de models.Model.
Este tipo de modelo también es almacenado en la base de datos, pero se espera que los datos sean útiles solo hasta que el asistente sea completado o cancelado. El servidor realiza limpiezas regulares de los datos viejos en los asistentes desde las tablas correspondientes de la base de datos.
El archivo todo_wizard/todo_wizard_model.py definirá los tres campos
que necesita: la lista de tareas que serán actualizadas, la persona
responsable, y la fecha límite, como se muestra aquí:
# -*- coding: utf-8 -*-
from openerp import models, fields, api
from openerp import exceptions # will be used in the code
import logging_logger = logging.getLogger(__name__)
class TodoWizard(models.TransientModel):
_name = 'todo.wizard'
task_ids = fields.Many2many('todo.task', string='Tasks')
new_deadline = fields.Date('Deadline to Set')
new_user_id = fields.Many2one('res.users',string='Responsible to Set')
No vale de que nada, si usa una relación uno a muchos tener que agregar el campo inverso muchos a uno. Debería evitar las relaciones muchos a uno entre los modelos transitorios y regulares, y para ello use relaciones muchos a muchos que tengan el mismo propósito sin la necesidad de modificar el modelo de tareas por hacer.
También esta agregando soporte al registro de mensajes. El registro se inicia con dos líneas justo después del TodoWizard, usando la librería estándar de registro de Python. Para escribir mensajes en el registro podrá usar:
_logger.debug('A DEBUG message')
_logger.info('An INFO message')
_logger.warning('A WARNING message')
_logger.error('An ERROR message')
Vea más ejemplos de su uso en este capítulo.
Formularios de asistente
La vista de formularios de asistente luce exactamente como los formularios regulares, excepto por dos elementos específicos:
- Puede usarse una sección
<footer>para colocar botones de acción. - Esta disponible un tipo especial de botón de cancelación para interrumpir el asistente sin ejecutar ninguna acción.
Este es el contenido del archivo todo_wizard/todo_wizard_view.xml:
<openerp>
<data>
<record id="To-do Task Wizard" model="ir.ui.view">
<field name="name">To-do Task Wizard</field>
<field name="model">todo.wizard</field>
<field name="arch" type="xml">
<form>
<div class="oe_right">
<button type="object" name="do_count_tasks" string="Count"/>
<button type="object" name="do_populate_tasks" string="Get All"/>
</div>
<field name="task_ids"/>
<group>
<group>
<field name="new_user_id"/>
</group>
<group>
<field name="new_deadline"/>
</group>
</group>
<footer>
<button type="object" name="do_mass_update" string="Mass Update"
class="oe_highlight"
attrs="{'invisible': [('new_deadline','=',False), ('new_user_id','=',False)]}"/>
<button special="cancel" string="Cancel"/>
</footer>
</form>
</field>
</record>
<!-- More button Action -->
<act_window id="todo_app.action_todo_wizard" name="To-Do Tasks Wizard"
src_model="todo.task" res_model="todo.wizard" view_mode="form"
target="new" multi="True"/>
</data>
</openerp>
La acción de ventana que ve en el XML agrega una opción al botón
"Más" del formulario de tareas por hacer, usando el atributo
src_model. target=new hace que se abra como una ventana de
dialogo.
También debe haber notado el atributo attrs en el botón "Mass Update" usado
para hacer al botón invisible hasta que sea seleccionada otra fecha
límite u otro responsable.
Así es como lucirá su asistente:
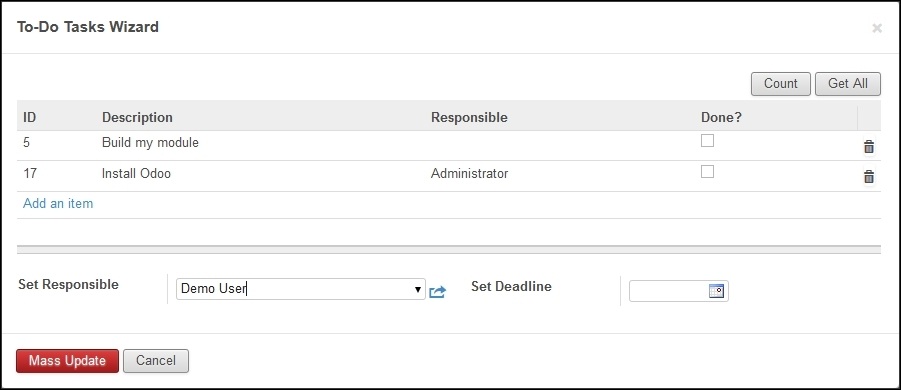
Gráfico 7.1 - Vista ToDo Tasks Wizard
Lógica de negocio del asistente
Luego necesita implementar las acciones ejecutadas al hacer clic en
el botón "Mass Update". El método que es llamado por el botón es
do_mass_update y debe ser definido en el archivo
todo_wizard/todo_wizard_model.py, como se muestra en el siguiente
código.
@api.multi
def do_mass_update(self):
self.ensure_one()
if not (self.new_deadline or self.new_user_id):
raise exceptions.ValidationError('No data to update!') #
else:
_logger.debug('Mass update on Todo Tasks %s',self.task_ids.ids)
if self.new_deadline:
self.task_ids.write({'date_deadline': self.new_deadline})
if self.new_user_id:
self.task_ids.write({'user_id': self.new_user_id.id})
return True
Nuestro código puede manejar solo una instancia del asistente al mismo
tiempo. Puede que haya usado @api.one, pero no es recomendable
hacerlo en los asistentes. En algunos casos querrá que el asistente
devuelva una acción de ventana, que le diga al cliente que hacer luego.
Esto no es posible hacerlo con @api.one, ya que esto devolverá una
lista de acciones en vez de una sola.
Debido a esto, prefiere usar @api.multi y luego use ensure_one()
para verificar que self representa un único registro. Debe tenerse en
cuenta que self es un registro que representa los datos en el formulario
del asistente. El método comienza validando si se ha dado una nueva fecha
límite o un nuevo responsable, de lo contrario arroja un error. Luego, se
hace una demostración de la escritura de un mensaje en el registro del
servidor. Si pasa la validación, escriba los nuevos valores dados a las
tareas seleccionadas. Esta usando el método de escritura en un conjunto de
registros, como los task_id a muchos campos para ejecutar una
actualización masiva.
Esto es más eficiente que escribir repetidamente en cada registro dentro de un bucle. Ahora trabajara en la lógica detrás de los dos botones en la parte superior. "Count" y "Get All".
Elevar excepciones
Cuando algo no esta bien, querrá interrumpir el programa con algún mensaje de error. Esto se realiza elevando una excepción. Odoo proporciona algunas clases de excepción adicionales a aquellas disponibles en Python. Estos son ejemplos de las más usadas:
from openerp import exceptions
raise exceptions.Warning('Warning message')
raise exceptions.ValidationError('Not valid message')
El mensaje de advertencia también interrumpe la ejecución pero puede parecer menos severo que un ValidationError. Aunque no es la mejor interfaz, les aprovechará de esto para mostrar un mensaje en el botón "Count":
@api.multi def do_count_tasks(self):
Task = self.env['todo.task']
count = Task.search_count([])
raise exceptions.Warning('There are %d active tasks.' % count)
Recarga automática de los cambios en el código
Cuando esta trabajando en el código Python, es necesario reiniciar el
servidor cada vez que el código cambia. Para hacer le la vida más fácil
a las personas que desarrollan esta disponible la opción --auto-reload.
Esta realiza un monitoreo del código fuente y lo recarga automáticamente si
es detectado algún cambio. Aquí se muestra un ejemplo de su uso:
$ ./odoo.py -d v8dev --auto-reload
Pero esta es una característica única en sistemas Linux. Si esta usando
Debian/Ubuntu, como se recomendó en el Capítulo 1,
entonces debe funcionar. Se requiere el paquete Python pyinotify, y debe
ser instalado a través de apt-get o pip, como se muestra a continuación:
Usando paquetes OS, ejecutando el siguiente comando:
$ sudo apt-get install python-pyinotify
Usando pip, posiblemente en un entorno virtual creado por el paquete
virtualenv, ejecutando el siguiente comando:
$ pip install pyinotify
Acciones en el dialogo del asistente
Ahora suponga que querrá tener un botón que selecciona automáticamente las todas las tareas por hacer para ahorrar le la tarea al usuario de tener que escoger una a una. Este es el objetivo de tener un botón "Get All" en el formulario. El código detrás de este botón tomará un conjunto de registros de tareas activas y los asignará a las tareas en el campo muchos a muchos.
Pero hay una trampa aquí. En las ventanas de dialogo, cuando un botón es presionado, la ventana de asistente es cerrada automáticamente. No se les presento este problema con el botón "Count" porque este usa una excepción para mostrar el mensaje; así que la acción falla y la ventana no se cierra.
Afortunadamente podrá trabajar este comportamiento para que retorne una acción al cliente que abra de nuevo el mismo asistente. Los métodos del modelo pueden retornar una acción para que el cliente web la ejecute, de la forma de un diccionario que describa la acción de ventana que será ejecutada. Este diccionario usa los mismos atributos que se usan para definir las acciones de ventana en el XML del módulo.
Usara una función de ayuda para el diccionario de la acción de ventana para abrirse de nuevo la ventana del asistente, así podrá ser usada de nuevo en varios botones, como se muestra a continuación:
@api.multi
def do_reopen_form(self):
self.ensure_one()
return {
'type': 'ir.actions.act_window',
'res_model': self._name, # this model
'res_id': self.id, # the current wizard record
'view_type': 'form',
'view_mode': 'form',
'target': 'new'
}
No es importante si la acción de ventana es cualquier otra cosa, como saltas a un formulario y registro específico, o abrir otro formulario de asistente para pedir al usuario el ingreso de más datos.
Ahora que el botón "Get All" puede realizar su trabajo y mantener al usuario trabajando en el mismo asistente:
@api.multi
def do_populate_tasks(self):
self.ensure_one()
Task = self.env['todo.task']
all_tasks = Task.search([])
self.task_ids = all_tasks # reopen wizard form on same wizard record
return self.do_reopen_form()
Aquí podrá ver como obtener una referencia a un modelo diferente, el
cual en este caso es todo.task, para ejecutar acciones en el. Los
valores del formulario del asistente son almacenados en un modelo
transitorio y pueden ser escritos y leídos como en los modelos regulares.
También podrá ver que el método fija el valor de``task_ids`` con la
lista de todas las tareas activas.
Note que como no hay garantía que self sea un único registro, lo
valida usando self.ensure_one(). No debe usar el decorador
@api.one porque envuelve el valor retornado en una lista. Debido a
que el cliente web espera recibir un diccionario y no una lista, no
funcionaría como es requerido.
Trabajar en el servidor
Usualmente su código del servidor se ejecuta dentro de un método
del modelo, como es el caso de do_mass_update() en el código
precedente. En este contexto, self representa el conjunto de registro
desde los cuales se actúa.
Las instancias de las clases del modelo son en realidad un conjunto de registros. Para las acciones ejecutadas desde las vistas, este será únicamente el registro seleccionado actualmente. Si es una vista de formulario, usualmente es un único registro, pero en las vistas de árbol, pueden ser varios registros.
El objeto self.env le permite acceder a su entorno de ejecución;
esto incluye la información de la sesión actual, como el usuario actual
y el contexto de sesión, y también acceso a todos los otros modelos
disponibles en el servidor.
Para explorar mejor la programación del lado del servidor, podrá usar la consola interactiva del servidor, donde tiene un entorno similar al que encontró dentro de un método del modelo.
Esta es una nueva característica de la versión 9. Ha sido portada como un módulo para la versión 8, y puede ser descargada en https://www.odoo.com/apps/modules/8.0/shell/. Solo necesita ser colocada en algún lugar en la ruta de sus add-ons, y no se requiere instalación, o puede usar los siguientes comandos para obtener el código desde GitHub y hacer que el módulo este disponibles es su directorio de add-ons personalizados:
$ cd ~/odoo-dev
$ git clone https://github.com/OCA/server-tools.git -b 8.0
$ ln -s server-tools/shell custom-addons/shell
$ cd ~/odoo-dev/odoo
Para usar esto, ejecute odoo.py desde la línea de comandos con la
base de datos a usar, como se muestra a continuación:
$ ./odoo.py shell -d v8dev
Puede ver la secuencia de inicio del servidor en la terminal culminando
con un el símbolo de entrada de Python >>>. Aquí, self representa
el registro para el usuario administrador como se muestra a
continuación:
>>> self res.users(1,)
>>> self.name u'Administrator'
>>> self._name 'res.users'
>>> self.env
<openerp.api.Environment object at 0xb3f4f52c>
En la sesión anterior, se hizo una breve inspección de su entorno.
self representa al conjunto de registro res.users el cual solo
contiene el registro con el ID 1 y el nombre Administrator. También
podrá confirmar el nombre del modelo del conjunto de registros con
self._name, y confirmar que self.env es una referencia para el
entorno.
Como es usual, puede salir de la usando Ctrl + D. Esto también cerrará el proceso en el servidor y le llevara de vuelta a la línea de comandos de la terminal.
La clase Model a la cual hace referencia self es de hecho un conjunto
de registros. Si se itera a través de un conjunto de registro se
retornará registros individuales.
El caso especial de un conjunto de registro con un solo registro es llamado "singleton". Los "singletons" se comportan como registros, y para cualquier propósito práctico con la misma cosa. Esta particularidad quiere decir que se puede usar un registro donde sea que se espere un conjunto de registros.
A diferencia de los conjuntos de registros multi elementos, los "singletons" pueden acceder a sus campos usando la notación de punto, como se muestra a continuación:
>>> print self.name Administrator
>>> for rec in self: print rec.name Administrator
En este ejemplo, se realiza un ciclo a través de los registros en el
conjunto self e imprime el contenido del campo name. Este contiene
solo un registro, por lo tanto solo se muestra un nombre. Como puede
ver, self es un "singleton" y se comporta como un registro, pero al
mismo tiempo es iterable como un conjunto de registros.
Usar campos de relación
Como ya ha visto, los modelos pueden tener campos relacionales: muchos a uno, uno a muchos, y muchos a muchos. Estos tipos de campos tienen conjuntos de registros como valores.
En en caso de muchos a uno, el valor puede ser un "singleton" o un conjunto de registros vacío. En ambos casos, podrá acceder a sus valores directamente. Como ejemplo, las siguientes instrucciones son correctas y seguras:
>>> self.company_id res.company(1,)
>>> self.company_id.name u'YourCompany'
>>> self.company_id.currency_id res.currency(1,)
>>> self.company_id.currency_id.name u'EUR'
Convenientemente un conjunto de registros vacío también se comporta como
un singleton, y el acceder a sus campos no retorna un error simplemente
un False. Debido a esto, podrá recorrer los registros usando la
notación de punto sin preocuparse por los errores de valores vacíos,
como se muestra a continuación:
>>> self.company_id.country_id res.country()
>>> self.company_id.country_id.name False
Consultar los modelos
Con self solo podrá acceder a al conjunto de registros del método.
Pero la referencia a self.env le permite acceder a cualquier otro
modelo.
Por ejemplo, self.env['res.partner'] devuelve una referencia al
modelo Partners (la cual es un conjunto de registros vacío). Por lo
tanto podrá usar search() y browse() para generar el conjunto
de registros.
El método search() toma una expresión de dominio y devuelve un
conjunto de registros con los registros que coinciden con esas
condiciones. Un dominio vacío [] devolverá todos los registros. Si
el modelo tiene el campo especial "active", de forma predeterminada solo
los registros que tengan active=True serán tomados en cuenta. Otros
argumentos opcionales están disponibles:
order: Es una cadena de caracteres usada en la clausulaORDER BYen la consulta a la base de datos. Usualmente es una lista de los nombres de campos separada por coma.limit: Fija el número máximo de registros que serán devueltos.offset: Ignora los primeros "n" resultados; puede usarse conlimitpara realizar la búsqueda de un bloque de registros a la vez.
A veces solo necesita saber el número de registros que cumplen con
ciertas condiciones. Para esto podrá usar search_count(), la cual
devuelve el conteo de los registros en vez del conjunto de registros.
El método browse() toma una lista de Ids o un único ID y devuelve un
conjunto con esos registros. Esto puede ser conveniente para los casos
en que ya sepa los Ids de los registros que desea.
Algunos ejemplos de su uso se muestran a continuación:
>>> self.env['res.partner'].search([('name','like','Ag')]) res.partner(7,51)
>>> self.env['res.partner'].browse([7,51]) res.partner(7,51)
Escribir en los registros
Los conjuntos de registros implementan el patrón de registro activo. Esto significa que podrá asignas les valores, y esos valores se harán permanentes en la base de datos. Esta es una forma intuitiva y conveniente de manipulación de datos, como se muestra a continuación:
>>> admin = self.env['res.users'].browse(1)
>>> admin.name = 'Superuser'
>>> print admin.name Superuser
Los conjuntos de registros tienes tres métodos para actuar sobre los
datos: create(), write(), unlink().
El método create() toma un diccionario para mapear los valores de
los campos y devuelve el registro creado. Los valores predeterminados
con aplicados automáticamente como se espera, como se puede observar
aquí:
>>> Partner = self.env['res.partner']
>>> new = Partner.create({'name':'ACME','is_company': True})
>>> print new res.partner(72,)
El método unlink() borra los registros en el conjunto, como se
muestra a continuación:
>>> rec = Partner.search([('name','=','ACME')])
>>> rec.unlink()
True
El método write() toma un diccionario para mapear los valores de los
registros. Estos son actualizados en todos los elementos del conjunto y
no se devuelve nada, como se muestra a continuación:
>>> Partner.write({'comment':'Hello!'})
Usar el patrón de registro activo tiene algunas limitaciones; solo
actualiza un registro a la vez. Por otro lado, el método write()
puede actualizar varios campos de varios registros al mismo tiempo
usando una sola instrucción de basa de datos. Estas diferencias deben
ser tomadas en cuenta en el momento cuando el rendimiento pueda ser un
problema.
También vale la pena mencionar a copy() para duplicar un registro
existente; toma esto como un argumento opcional y un diccionario con los
valores que serán escritos en el registro nuevo. Por ejemplo, para crear
un usuario nuevo copiando lo desde "Demo User":
>>> demo = self.env.ref('base.user_demo')
>>> new = demo.copy({'name': 'Daniel', 'login': 'dr', 'email':''})
>>> self.env.cr.commit()
Recuerde que los campos con el atributo copy=False no serán tomados
en cuenta.
Transacciones y SQL de bajo nivel
Las operaciones de escritura en la base de datos son ejecutadas en el contexto de una transacción de base de datos. Usualmente no tiene que preocuparse por esto ya que el servidor se encarga de ello mientras se ejecutan los métodos del modelo.
Pero en algunos casos, necesitara un mayor control sobre la
transacción. Esto puede hacerse a través del cursor self.env.cr de
la base de datos, como se muestra a continuación:
self.env.cr.commit(): Este escribe las operaciones de escritura cargadas de la transacción.self.env.savepoint(): Este fija un punto seguro en la transacción para poder revertirla.self.env.rollback(): Este cancela las operaciones de escritura de la transacción desde el último punto seguro o todo si no fue creado un punto seguro.Truco
En una sesión de la terminal, la manipulación de los datos no se hará efectiva hasta no usar
self.env.cr.commit().
Con el método del cursor execute(), podrá ejecutar SQL
directamente en la base de datos. Este toma una cadena de texto con la
sentencia SQL que se ejecutará y un segundo argumento opcional con una
tupla o lista de valores para ser usados como parámetros en el SQL.
Estos valores serán usados donde se encuentre el marcador %s.
Si esta usando una sentencia SELECT, debería retornar los registros. La
función fetchall() devuelve todas las filas como una lista de tuplas
y dictfetchall() las devuelve como una lista de diccionarios, como
se muestra en el siguiente ejemplo:
>>> self.env.cr.execute("SELECT id, login FROM res_users WHERE login=%s OR id=%s",('demo',1))
>>> self.env.cr.fetchall()
[(4, u'demo'), (1, u'admin')]
También es posible ejecutar instrucciones en lenguaje de manipulación de
datos (DML) como UPDATE e INSERT. Debido a que el servidor mantiene en
memoria (cache) los datos, estos puede hacerse inconsistente con los
datos reales de la base de datos. Por lo tanto, cuando se use DML, la
memoria (cache) debe ser limpiada después de su uso, a través de
self.env.invalidate_all().
Advertencia
Ejecutar SQL directamente en la base de datos puede tener como consecuencia la generación de inconsistencias en los datos. Debe usarse solo cuando tenga la seguridad de lo que esta haciendo.
Trabajar con hora y fecha
Por razones históricas, los valores de fecha, y de fecha y hora se manejan como cadenas en vez de sus tipos correspondientes en Python. Además los valores de fecha y hora de almacenan en la base de datos en hora UTC. Los formatos usados para representar las cadenas son definidos por:
openerp.tools.misc.DEFAULT_SERVER_DATE_FORMAT
openerp.tools.misc.DEFAULT_SERVER_DATETIME_FORMAT
Estas se esquematizan como %Y-%m-%d y %Y-%m-%d %H:%M:%S
respectivamente.
Para ayudar a manejar las fechas, fields.Date y fields.Datetime
proveen algunas funciones. Por ejemplo:
>>> from openerp import fields
>>> fields.Datetime.now()
'2014-12-08 23:36:09'
>>> fields.Datetime.from_string('2014-12-08 23:36:09')
datetime.datetime(2014, 12, 8, 23, 36, 9)
Dado que las fechas y horas son tratadas y almacenadas por el servidor en formato UTC nativo, el cual no toma en cuenta la zona horaria y probablemente es diferente a la zona horaria del usuario, a continuación se muestran algunas otras funciones que pueden ayudar con esto:
fields.Date.today(): Este devuelve una cadena con la fecha actual en el formato esperado por el servidor y usando UTC como referencia. Es adecuado para calcular valores predeterminados.fields.Datetime.now(): Este devuelve una cadena con la fecha y hora actual en el formato esperado por el servidor y usando UTC como referencia. Es adecuado para calcular valores predeterminados.fields.Date.context_today(record, timestamp=None): Este devuelve una cadena con la fecha actual en el contexto de sesión. El valor de la zona horaria es tomado del contexto del registro, y el parámetro opcional es la fecha y hora en vez de la hora actual.fields.Datetime.context_timestamp(record, timestamp): Este convierte una hora y fecha nativa (sin zona horaria) en una fecha y hora consciente de la zona horaria. La zona horaria se extrae del contexto del registro, de allí el nombre de la función.
Para facilitar la conversión entre formatos, tanto el objeto
fields.Date como fields.Datetime proporcionan estas funciones:
from_string(value): convierte una cadena a un objeto fecha o de fecha y hora.to_string(value): convierte un objeto fecha o de fecha y hora en una cadena en el formato esperado por el servidor.
Trabajar con campos de relación
Mientras se usa el patrón de registro activo, se pueden asignar conjuntos de registros a los campos relacionales.
- Para un campo muchos a uno, el valor asignado puede ser un único
registro (un conjunto de registros
singleton). - Para campos a-muchos, sus valores pueden ser asignados con un conjunto de registros, reemplazando la lista de registros enlazados, si existen, con una nueva. Aquí se permite un conjunto de registros de cualquier tamaño.
Mientras se usan los métodos create() o write(), donde se asigna
los valores usando diccionarios, no es posible asignar conjuntos de
registros a los valores de los campos relacionales. Se debería usar el
ID correspondiente o la lista de Ids.
Por ejemplo, en ves de self.write({'user_id': self.env.user}),
debería usar self.write({'user_id':self.env.user.id}).
Manipular los conjuntos de registros
Seguramente querrá agregar, eliminar o reemplazar los elementos en estos campos relacionados, y esto lleva a la pregunta: ¿como se pueden manipular los conjuntos de registros?
Los conjuntos de registros son inmutables pero pueden ser usados para componer conjuntos de registros nuevos. A continuación se muestran algunas de operaciones soportadas:
rs1 | rs2: Como resultado se tendrá un conjunto con todos los elementos de ambos conjuntos de registros.rs1 + rs2: Esto también concatena ambos conjuntos en uno.rs1 & rs2: Como resultado se tendrá un conjunto con los elementos encontrados, que coincidan, en ambos conjuntos de registros.rs1 – rs2: Como resultado se tendrá un conjunto con los elementos ders1que no estén presentes enrs2.
También se puede usar notación de porción, como se muestra a continuación:
rs[0]yrs[-1], retornan el primer elemento y el último elemento.rs[1:], devuelve una copia del conjunto sin el primer elemento. Este produce los mismos registros quers – rs[0]pero preservando el orden.
En general, cuando se manipulan conjuntos de registro, debe asumir que el orden del registro no es preservado. Aun así, la agregación y en "slicing" son conocidos por mantener el orden del registro.
Podrá usar estas operaciones de conjuntos para cambiar la lista, eliminando o agregando elementos. Puede observar esto en el siguiente ejemplo:
self.task_ids |= task1: Esto agrega el elementotask1si no existe en el conjunto de registro.self.task_ids -= task1: Elimina la referencia atask1si esta presenta en el conjunto de registro.self.task_ids = self.task_ids[:-1]: Esto elimina el enlace del último registro.
Una sintaxis especial es usada para modificar a muchos campos, mientras
se usan los métodos create() y write() con valores en un
diccionario.
Esto fue explicado en el Capítulo 4, en la sección Configurar valores para los campos de relación.
Se hace referencia a las siguientes operaciones de ejemplo equivalentes
a las precedentes usando write():
self.write([(4, task1.id, False)]): Agregatask1al miembro.self.write([(3, task1.id, False)]): Desconecta (quita el enlace)task1.self.write([(3, self.task_ids[-1].id, False)]): Desconecta (quita en enlace) el último elemento.
Otras operaciones de conjunto de registros
Los conjuntos de registro soportan operaciones adicionales.
Podrá verificar si un registro esta o no incluido en un conjunto, haciendo lo siguiente: record in recordset, record not in recordset. También estas disponibles estas operaciones:
recordset.ids: Esto devuelve la lista con los Ids de los elementos del conjunto.recordset.ensure_one(): Verifica si es un único registro (singleton); si no lo es, arroja una excepciónValueError.recordset.exists(): Devuelve una copia solamente con los registros que todavía existen.recordset.filtered(func): Devuelve un conjunto de registros filtrado.recordset.mapped(func): Devuelve una lista de valores mapeados.recordset.sorted(func): Devuelve un conjunto de registros ordenado.
A continuación se muestran algunos ejemplos del uso de estas funciones:
>>> rs0 = self.env['res.partner'].search([])
>>> len(rs0) # how many records?
68
>>> rs1 = rs0.filtered(lambda r: r.name.startswith('A'))
>>> print rs1 res.partner(3, 7, 6, 18, 51, 58, 39)
>>> rs2 = rs1.filtered('is_company')
>>> print rs2 res.partner(7, 6, 18)
>>> rs2.mapped('name') [u'Agrolait', u'ASUSTeK', u'Axelor']
>>> rs2.mapped(lambda r: (r.id, r.name)) [(7, u'Agrolait'), (6, u'ASUSTeK'), (18, u'Axelor')]
>>> rs2.sorted(key=lambda r: r.id, reverse=True)
res.partner(18, 7, 6)
El entorno de ejecución
El entorno provee información contextual usada por el servidor. Cada
conjunto de registro carga su entorno de ejecución en self.env con
estos atributos:
env.cr: Es el cursor de base de datos usado actualmente.env.uid: Este es el ID para el usuario de la sesión.env.user: Es el registro para el usuario de la sesión.env.context: Es un diccionario inmutable con un contexto de sesión.
El entorno es inmutable, por lo tanto no puede ser modificado. Pero podrá crear entornos modificables y luego usarlos para ejecutar acciones.
Para esto pueden usarse los siguientes métodos:
env.sudo(user): Si esto es provisto con un registro de usuario, devuelve un entorno con este usuario. Si no se proporciona un usuario, se usa el usuario de administración, el cual permite ejecutar diferentes sentencias pasando por encima de las reglas de seguridad.env.with_context(dictionary): Reemplaza el contexto con uno nuevo.env.with_context(key=value,...): Fija los valores para las claves en el contexto actual.
La función env.ref() toma una cadena con un ID externo y devuelve un
registro, como se muestra a continuación.
>>> self.env.ref('base.user_root')
res.users(1,)
Métodos del modelo para la interacción con el cliente
Ha visto los métodos del modelo más importantes usados para generar los conjuntos de registros y como escribir en ellos. Pero existen otros métodos disponibles para acciones más específicas, se muestran a continuación:
read([fields]): Es similar a browse, pero en vez de un conjunto de registros, devuelve una lista de filas de datos con los campos dados como argumentos. Cada fila es un diccionario. Proporciona una representación serializada de los datos que puede enviarse a través de protocolos RPC y esta previsto que sea usada por los programas del cliente y no por la lógica del servidor.search_read([domain], [fields], offset=0, limit=None, order=None): Ejecuta una operación de búsqueda seguida por una lectura a la lista del registro resultante. Esta previsto que sea usado por los cliente RPC y ahorrarles el trabajo extra cuando se hace primero una búsqueda y luego una lectura.load([fields], [data]): Es usado para importar datos desde un archivo CSV. El primer argumento es la lista de campos que se importarán, y este se asigna directamente a la primera fila del CSV. El segundo argumento es una lista de registros, donde cada registro es una lista de valores de cadena de caracteres para para analizar e importar, y este se asigna directamente a las columnas y filas de los datos del CSV. Implementa las características de importación de datos CSV descritas en el Capítulo 4, como el soporte para Ids externos. Es usado por la característica Import del cliente web. Reemplaza el método obsoletoimport_data.export_data([fields], raw_data=False): Es usado por la función Export del cliente web. Devuelve un diccionario con una clave de datos que contiene la lista "data-a" de filas. Los nombres de los campos pueden usar los sufijos.idy/idusados en los archivos CSV. El argumento opcionalraw_datapermite que los valores de los datos sean exportados con sus tipos en Python, en vez la representación en cadena de caracteres usada en CSV.
Los siguientes métodos son mayormente usados por el cliente web para representar la interfaz y ejecutar la interacción básica:
name_get(): Devuelve una lista de tuplas (ID, name) con un texto que representa a cada registro. Es usado de forma predeterminada para calcular el valordisplay_name, que provee la representación de texto de los campos de relación. Puede ser ampliada para implementar representaciones de presentación personalizadas, como mostrar el código del registro y el nombre en vez de solo el nombre.name_search(name='', args=None, operator='ilike', limit=100): Este también devuelve una lista de tuplas (ID, name), donde el nombre mostrado concuerda con el texto en el argumentoname. Es usado por la UI mientras se escribe en el campo de relación para producir la lista de registros sugeridos que coinciden con el texto escrito. Se usa para implementar la búsqueda de productos, por nombre y por referencia mientras se escribe en un campo para seleccionar un producto.name_create(name): Crea un registro nuevo únicamente con el nombre de título. Se usa en el UI para la característica de creación rápida, donde puede crear rápidamente un registro relacionado con solo proporcionar el nombre. Puede ser ampliado para proveer configuraciones predeterminadas mientras se crean registros nuevos a través de esta característica.default_get([fields]): Devuelve un diccionario con los valores predeterminados para la creación de un registro nuevo. Los valores predeterminados pueden depender de variables como en usuario actual o el contexto de la sesión.fields_get(): Usado para describir las definiciones del campo, como son vistas en la opción Campos de Vista del menú de desarrollo.fields_view_get(): Es usado por el cliente web para devolver la estructura de la vista de la UI. Puede darse el ID de la vista como un argumento o el tipo de vista que querrá usandoview_type='form'.Vea el siguiente ejemplo:
rset.fields_view_get(view_type='tree')
Sobre escribir los métodos predeterminados
Ha aprendido sobre los métodos estándares que provee la API. Pero lo que podrá hacer con ellos no termina allí! También podrá ampliarlos para agregar comportamientos personalizados a sus modelos.
El caso más común es ampliar los métodos create() y write().
Puede usarse para agregar la lógica desencadenada en cualquier momento
que se ejecuten estas acciones. Colocando su lógica en la sección
apropiada de los métodos personalizados, podrá hacer que el se ejecute
antes o después que las operaciones principales.
Usando el modelo TodoTask como ejemplo, podrá crear un create()
personalizado, el cual puede ser de la siguiente forma:
@api.model
def create(self, vals):
# Code before create
# Can use the `vals
dict new_record = super(TodoTask, self).create(vals)
# Code after create
# Can use the `new` record created
return new_record
Un método write() personalizado seguiría esta estructura:
@api.multi
def write(self, vals):
# Code before write
# Can use `self`, with the old values
super(TodoTask, self).write(vals)
# Code after write
# Can use `self`, with the new (updated) values
return True
Estos son ejemplos comunes de ampliación, pero cualquier método estándar disponibles para un modelo puede ser heredado en un forma similar para agregar lo a su lógica personalizada.
Estas técnicas abren muchas posibilidades, pero recuerde que otras herramientas que se ajustan mejor a tareas específicas también esta disponibles, y deben darse le prioridad:
- Para tener un valor de campo calculado basado en otro, debe usar campos calculados. Un ejemplo de esto es calcular un total cuando los valores de las líneas cambian.
- Para tener valores predeterminados de campos calculados dinámicamente, podrá usar un campo predeterminado enlazado a una función en vez de a un valor escalar.
- Para fijar valores en otros campos cuando un campos cambia, podrá
usar funciones
on-change. Un ejemplo de esto es cuando escoge un cliente para fijar el tipo de moneda en el documento para el socio correspondiente, el cual puede luego ser cambiado manualmente por el usuario. Tenga en cuenta queon-changesolo funciona desde las interacciones de ventana y no directamente en las llamadas de escritura. - Para las validaciones, podrá funciones de restricción decoradas
con
@api.constraints(fdl1,fdl2,...). Estas son como campos calculados pero se espera que arrojen errores cuando las condiciones no son cumplidas en vez de valores calculados.
Decoradores de métodos del Modelo
Durante su jornada, los métodos que ha encontrado usan los
decoradores de la API como @api.one. Estos son importantes para que
el servidor sepa como manejar los métodos. Ya ha dado alguna
explicación de los decoradores usados; ahora recapitule sobre
aquellos que están disponibles y de como deben usarse:
@api.one: Este alimenta a la función con un registro a la vez. El decorador realiza la iteración del conjunto de registros por usted y se garantiza queselfsea un singleton. Este es el que debe usar si su lógica solo requiere trabajar con cada registro. También agrega el valor retornado de la función en una lista en cada registro, la cual puede tener efectos secundarios no intencionados.@api.multi: Este controla un conjunto de registros. Debe usarlo cuando su lógica pueda depender del conjunto completo de registros y la visualización de registros aislados no es suficiente o cuando necesita que el valor de retorno no sea una lista como un diccionario con una acción de ventana. Este es el que más se usa en la práctica ya que@api.onetiene algunos costos y efectos de empaquetado de listas en los valores del resultado.@api.model: Este es un método estático de nivel de clase, y no usa ningún dato de conjunto de registros. Por consistencia,selfaún es un conjunto, pero su contenido es irrelevante.@api.returns(model): Este indica que el método devuelve instancias del modelo en el argumento para el modelo actual, comores.partneroself.
Los decoradores que tiene propósitos más específicos y que fueron explicados en el Capítulo 5, se muestran a continuación:
@api.depends(fld1,...): Este es usado por funciones de campos calculados para identificar los cambios en los cuales se debe realizar el (re) calculo.@api.constraints(fld1,…): Este es usado por funciones de validación para identificar los cambios en los que se debe realizar la validación.@api.onchange(fld1,...): Este es usado por funcioneson-changepara identificar los campos del formulario que detonarán la acción.
En particular, los métodos on-change pueden enviar mensajes de
advertencia a la interfaz. Por ejemplo, lo siguiente podría advertir al
usuario que la cantidad ingresada del producto no esta disponible, sin
impedir al usuario continuar. Esto es realizado a través de un método
return con un diccionario que describa el siguiente mensaje:
return {
'warning': {
'title': 'Warning!',
'message': 'The warning text'
}
}
Depuración
Sabe que una buena parte del trabajo de desarrollo es la depuración del código. Para hacer esto frecuentemente hace uso del editor de código que puede fijar pontos de quiebre y ejecutar su programa paso a paso. Hacer esto con Odoo es posible pero tiene sus dificultades.
Si esta usando Microsoft Windows como su estación de trabajo, configurar un entorno capaz de ejecutar en código de Odoo desde la fuente no es una tarea trivial. Además el hecho que Odoo sea un servidor que espera llamadas de un cliente para actuar, lo hace diferente a la depuración de programas del lado del cliente.
Mientras que esto puede ser realizado con Odoo, puede decirse que no es la forma más pragmática de resolver el asunto. Hará una introducción sobre algunas estrategias básicas para la depuración, las cuales pueden ser tan efectivas como algunos IDEs sofisticados, con un poco de práctica.
La herramienta integrada para la depuración de Python, pdb, puede hacer un
trabajo decente de depuración. Podrá fijar un punto de quiebre insertando
la siguiente línea en el lugar deseado:
import pdb; pdb.set_trace()
Ahora reinicie el servidor para que se cargue la modificación del código. Tan
pronto como la ejecución del código alcance la línea, una (pdb) linea de entrada
de Python será mostrada en la ventana de la terminal en la cual el servidor se
esta ejecutando, esperando por el ingreso de datos.
Esta línea de entrada funciona como una línea de comandos de Python, donde puede ejecutar cualquier comando o expresión en el actual contexto de ejecución. Esto significa que las variables actuales pueden ser inspeccionadas e incluso modificadas. Estos son los comandos disponibles más importantes:
h: Es usado para mostrar un resumen de la ayuda del comandopdb.p: Es usado para evaluar e imprimir una expresión.pp: Este es para una impresión más legible, la cual es útil para los diccionarios y listas muy largos.l: Lista el código alrededor de la instrucción que será ejecutada a continuación.n(next): Salta hasta la próxima instrucción.s(step): Salta hasta la instrucción actual.c(continue): Continua la ejecución normalmente.u(up): Permite moverse hacia arriba de la pila de ejecución.d(down): Permite moverse hacia abajo de la pila de ejecución.
El servidor Odoo también soporta la opción --debug. Si se usa, el servidor
entrara en un modo post mortem cuando encuentre una excepción, en la línea
donde se encuentre el error. Es una consola pdb y les permite inspeccionar el
estado del programa en el momento en que es encontrado el error.
Existen alternativas al depurador de Python. Puede provee los mismos comandos
que pdb y funciona en terminales de solo texto, pero usa una visualización
gráfica más amigable, haciendo que la información útil sea más legible como
las variables del contexto actual y sus valores.
Gráfico 7.2 - Vista del modelo todo.task
Puede ser instalado a través del sistema de paquetes o por pip, como se muestra
a continuación:
$ sudo apt-get install python-pudb # using OS packages
$ pip install pudb # using pip, possibly in a virtualenv
Funciona como pdb; solo necesita usar pudb en vez de pdb en el código.
Otra opción es el depurador Iron Python, ipdb, el cual puede ser instalado:
$ pip install ipdb
A veces solo necesita inspeccionar los valores de algunas
variables o verificar si algunos bloques de código son ejecutados. Una
sentencia print de Python puede perfectamente hacer el trabajo sin
parar el flujo de ejecución. Como esta ejecutando el servidor en una
terminal, el texto impreso será mostrado en la salida estándar. Pero no
será guardado en los registros del servidor si esta siendo escrito en un
archivo.
Otra opción a tener en cuenta es fijar los mensajes de registros de los
niveles de depuración en puntos sensibles de su código si siente
que podrá necesitar investigar algunos problemas en la instancia de
despliegue. Solo se requiere elevar el nivel de registro del servidor a
DEBUG y luego inspeccionar los archivos de registro.
Resumen
En los capítulos anteriores, vio como construir modelos y diseñar vistas. Aquí fue un poco más allá para aprender como implementar la lógica de negocio y usar conjuntos de registros para manipular los datos del modelo.
También pudo ver como la lógica de negocio interactúa con la interfaz y aprendió a crear ayudantes que dialoguen con el usuario y sirvan como una plataforma para iniciar procesos avanzados.
En el próximo capítulo, se enfocara nuevamente en la interfaz, y
aprenderá como crear vistas kanban avanzadas y a diseñar sus propios
reportes de negocio.